- Published on
Docker Model Runner: Local GenAI with Docker Desktop
- Authors

- Name
- Petros Savvakis
- @PetrosSavvakis
Docker Model Runner: Local GenAI with Docker Desktop
TL;DR
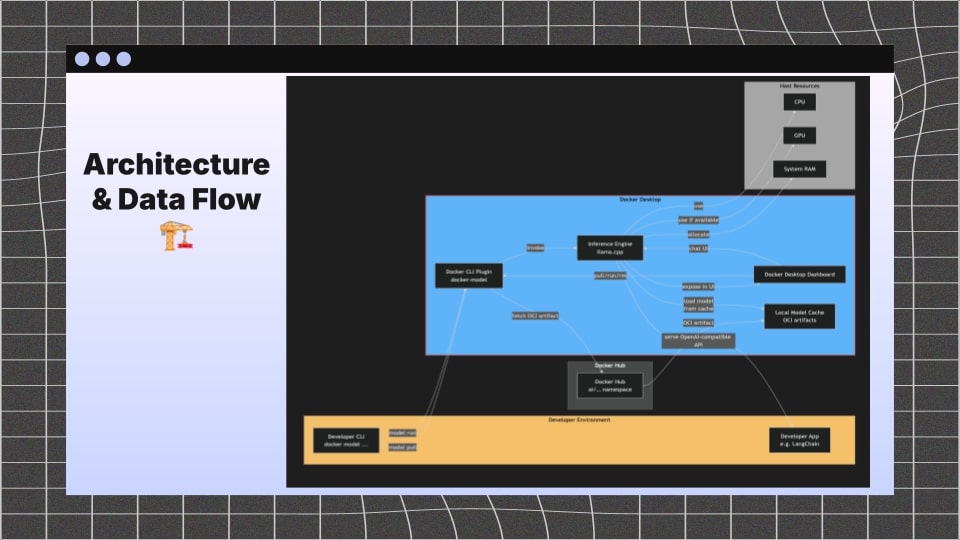
Docker Model Runner (DMR) is a beta in Docker Desktop v4.40+ that converts any dev machine into a GenAI playground. You can docker model pull/run an OCI packaged LLM from Docker Hub, and a lightweight host side engine (llama.cpp under the hood) exposes an OpenAI compatible API.
It caches models on disk, loads them to CPU/GPU on demand, and you can hit the endpoints from inside or outside containers—perfect for notebooks, micro services, or even a containerised IDE.
What is Docker Model Runner?
DMR is Docker native GenAI plumbing: it ships a host process that speaks the same OpenAI chat/completions/embeddings schema, but the model lives in a Docker managed cache you control. Think of it as docker run, but for models. No extra Kubernetes, no external SaaS credentials—just Docker Desktop and a supported GPU/CPU.
Key features at a glance
- CLI + GUI parity – docker model pull|run|list|rm|logs plus Dashboard controls.
- OCI packaged models – grab ai/llama3:8b-q4 (or any image under ai namespace) directly from Docker Hub.
- Host side inference – llama.cpp runs beside—not inside—your containers, using CPU, Apple Silicon, or NVIDIA GPU.
- OpenAI compatible endpoints – reachable via model runner.docker.internal with configurable port (from containers)
- Unix socket or TCP on the host.
- Smart resource management – models are disk-cached on first pull, loaded to RAM only when requested, then evicted when idle.
Presentation Slides
Following are some slides from my recent presentation at the Docker Athens Meetup, where I introduced Docker Model Runner to the local developer community:



Conclusion
Docker Model Runner brings one command GenAI to every developer workflow, letting you prototype LLM powered features without external dependencies or cloud costs. Pair it with Compose, Test Containers, or even a browser based IDE in a container—the same OpenAI style calls work everywhere. Grab the beta, pull an ai model, and start chatting—all within the toolchain you already know.